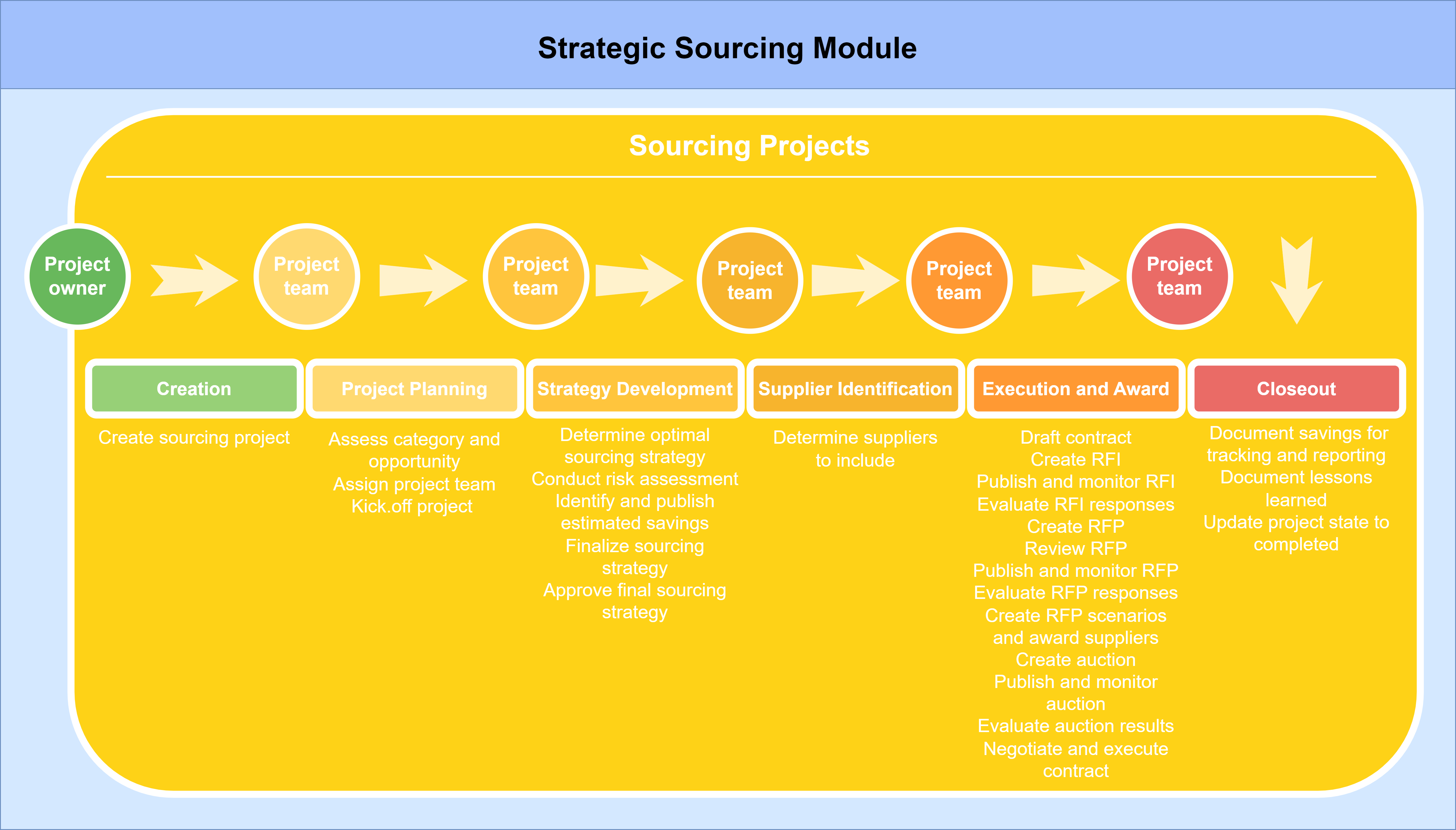
This app template was built for the SAP Ariba Sourcing process. This is an end-to-end process which usually starts with the creation of a sourcing project. Then, the standard project events are created and executed. These events comprise the basic steps needed for a sourcing project, such as:
Finally a contract is generated and the sourcing project is completed.
Please note that when creating a sourcing project in SAP Ariba, the user must select one Template for the project. These templates include predefined Phases and its Tasks, plus the Documents and Events that will be included in the project.
The following list shows the usual Activities that will be performed in an SAP Ariba sourcing project. All of them happen after the first activity which is Create sourcing project. These activities are also divided into several Phases as shown below:
Phase: Project Planning
Phase: Strategy Development
Phase: Supplier Identification
Phase: Execution and Award
Phase: Closeout
The graphic below briefly shows a standard template sourcing process in SAP Ariba:
The following tags are available by default.
| Tag | Description |
|---|---|
| Sourcing projects with baseline spend changes | Cases where the Baseline spend was either increased or decreased. |
| Sourcing projects with project reason changes | Cases which include an activity where their Description indicates the sourcing project reason has changed. |
| Sourcing projects reopened | Cases which include an activity where their Description indicates the sourcing project reason has been reopened. |
| Sourcing projects with more than one RFP | Cases which contain more than one 'RFP' event. |
| Sourcing projects with more than one RFI | Cases which contain more than one 'RFI' event. |
| Sourcing projects with more than one RFQ | Cases which contain more than one RFQ event. |
| Sourcing projects without contract associated | Cases which do not contain contracts. |
The following due dates are available by default.
| Due date | Description |
|---|---|
| Sourcing project start due date | Compares the date when the sourcing project should start (planned start date) with the date it actually started. |
| Sourcing project ended after planned due date | This due date compares the date when the sourcing project should finish (planned end date) with the date it actually ended. |
This app template uses SAP Ariba as source system. Extraction for the source system is done using a custom extractor, which extracts data from SAP Ariba in CSV format using Ariba APIs. Both full data sets and delta extraction are supported. The generated files can be loaded using CData Sync. Make sure you have a valid license for CData Sync and have installed CData Sync.
This app template is built for SAP Ariba v.2301 or newer. SAP Ariba is a Software as a Service (SaaS) and it gets constant updates that are deployed quarterly, naming its versions with the last two digits of the year directly followed by the month of the release (i.e. January 2023 release: v.2301).
SAP Ariba Strategic Sourcing module is mandatory.
As mentioned before, this app template was built and tested to work with SAP Ariba v.2301. However, it was designed to work with tables that are the backbone of the sourcing process so it is probable that it will remain compatible with the next multiple iterations of the system. It is recommended to review the documentation of each new release to be aware of the changes that could happen in the tables.
An extractor is developed in Python that allows to extract data from SAP Ariba in CSV format using Ariba APIs. Note that due to limitations of the Ariba APIs regarding the number of requests and the number of records extracted per request, this extraction might take longer than expected.
For the extractor and its documentation, download the SAP_Ariba_extractor.zip. Follow the instructions in the documentation to install and configure the extractor. Execute the extractor for all sourcing models.
To set up the destination connection, follow the steps as defined in Create a destination connection (Automation Cloud). Note: If you are using Automation Suite, make sure to select AUTOMATION SUITE as the DELIVERY option and select the correct version of Automation Suite you are using.
To create the Job in CData make sure to follow the steps below.
In the Advanced tab in the Job Settings panel, edit the following settings:
If you are using Automation Suite, set the Destination Schema in the Settings panel on the overview tab. Use the schema name you retrieved when you created the destination connection.
After the data has been successfully loaded, the Process Mining platform needs to start the data ingestion process. This is done by calling the End of Upload API. In order to set this up, follow the steps below:
| Step | Action |
|---|---|
| 1 | Go to the Events tab in the Job Settings panel of the job you are creating |
| 2 | Edit the Post-Job Event section to add the code displayed below after <!-- Code goes here -- >. Do not modify the api:info details that are shown by default. |
| 3 | Fill out the End of Upload API with the value provided. |
| 4 | In case you need a debugging log for this call, uncomment the two lines provided in the code below and provide a location for the log file. |
| 5 | Click on Save Changes. |
<api:set attr="http.url" value="END_OF_UPLOAD_API"/>
<!-- <api:set attr="http.verbosity" value="5"/> -->
<!-- <api:set attr="http.logfile" value="D:/mydir/cdata_log.txt"/> -->
<api:call op="httpPost" in="http"/>
Once the job is correctly setup, go to Task tab, click + Add Tasks, enable the Custom Query option and paste the following queries (each query needs to maintain the semicolon at the end). Make sure you save all changes.
REPLICATE [Sourcing_project_details] ([internalId] VARCHAR(255), [beginDate] VARCHAR(255), [endDate] VARCHAR(255), [plannedEndDate] VARCHAR(255), [plannedStartDate] VARCHAR(255), [templateProjectTitle] VARCHAR(255), PRIMARY KEY ([internalId]), [lastModified] DATETIME) SELECT * FROM [Sourcing_project_details];
REPLICATE [Sourcing_project_events] ([internalId] VARCHAR(255), [createDate] VARCHAR(255), [description] VARCHAR(255), [docType] VARCHAR(255), [iconType] VARCHAR(255), [owner] VARCHAR(255), [projectId] VARCHAR(255), [status] VARCHAR(255), [title] VARCHAR(255), [type] VARCHAR(255), PRIMARY KEY ([internalId]), [lastModified] DATETIME) SELECT * FROM [Sourcing_project_events];
REPLICATE [Sourcing_projects_history] ([InternalId] VARCHAR(255), [BaselineSpendAmount] VARCHAR(255), [BaselineSpendCurrency] VARCHAR(255), [ClientDescription] VARCHAR(255), [CommodityName] VARCHAR(255), [OwnerName] VARCHAR(255), [ParentDocumentInternalId] VARCHAR(255), [RegionDescription] VARCHAR(255), [Status] VARCHAR(255), [TimeCreated] VARCHAR(255), [Title] VARCHAR(255), PRIMARY KEY ([InternalId]), [lastModified] DATETIME) SELECT * FROM [Sourcing_projects_history];
REPLICATE [Currency_conversion_rates] SELECT * FROM [Currency_conversion_rates];
The SAP Ariba extractor supports incremental extraction. With incremental extraction, only the data that has changed since the last extraction is extracted. This will reduce the amount of data that needs to be extracted and thus the extraction time.
The steps to configure incremental extraction are described below. You are advised to configure the incremental extraction as an additional extraction configuration, to make sure that you can also perform a full extraction as needed. See also section limitations.
Please note that when using Automation Cloud, you will need an additional staging database to store data and merge incremental data with the existing data. See Incremental extraction prerequisites in Automation Cloud for more information. This also implies that the CData Sync job for full extractions will need to be configured to use the staging database as destination.
To configure incremental extraction in the extractor, you can use the --delta argument. This requires that a full extraction has been done before. You are also advised to use a different output location for incremental extracts. Please see the README file that is included with the extractor for more details on how to specify those arguments.
To configure incremental extraction in CData Sync, you will need to configure an additional job to merge the incremental extracted data into the existing dataset. You can use the same steps described above to setup a new job in CData Sync, but with the following changes:
When using Automation Cloud with a staging database, you will need an additional CData Sync job to load the data from the staging database into the Process Mining platform. Make sure the source connection is the staging database. To configure the destination connection, see Create a destination connection (Automation Cloud).
The following tables include the list of fields per input table, their description and data type to be used.
The following table provides an overview of the different field types and their default format settings.
| Field type | Description |
|---|---|
| boolean | true, false, 1, 0 |
| date | yyyy-mm-dd |
| datetime | yyyy-mm-dd hh:mm:ss |
| double | Decimal separator: . (dot); thousand separator: none |
| integer | Thousand separator: none |
| text | N/A |
The following tables are extracted from the source system:
Contains sourcing projects transactional information.
| Field | Type | Description |
|---|---|---|
| InternalId | text | Unique identifier of the sourcing project |
| BaselineSpendAmount | double | Indicates the amount had to spend in the sourcing project |
| BaselineSpendCurrency | text | Indicates the currency of the baseline spend amount in the sourcing project |
| ClientDescription | text | Used to specify the department in the organization involved in the project |
| CommodityName | text | The commodity of the sourcing project, an organization might refer to commodities as categories (e.g. suppliers categorization) |
| OwnerName | text | The user who owns the sourcing project |
| ParentDocumentInternalId | text | Indicates the unique identifier of the predecessor document related to the sourcing project. (e.g. another sourcing project ID; a sourcing request ID) |
| RegionDescription | text | The geographic region belonging to the sourcing project |
| Status | text | Sourcing project state in the process |
| TimeCreated | timestamp | Timestamp on which the sourcing project was created |
| Title | text | User-friendly name of the sourcing project |
Filtering: Sourcing_projects is the only table that has a date-time filter. This table will then provide the Sourcing_project_IDs that will be used as a filter for all the other transactional tables. Master data tables, as usual, are not being filtered.
Stores sourcing projects attributes information.
| Field | Type | Description |
|---|---|---|
| internalId | text | Unique identifier of the sourcing project |
| beginDate | timestamp | Date when the project actually started |
| endDate | timestamp | Date when the project actually ended |
| plannedEndDate | timestamp | The date planned to end the project |
| plannedStartDate | timestamp | The date planned to start the sourcing project |
| templateProjectTitle | text | Predefined model that the sourcing project uses as a base to be created |
Contains information of all sourcing project related documents such as RFPs, RFIs, RFQs and Contract workspaces.
| Field | Type | Description |
|---|---|---|
| internalId | text | Unique identifier of the project documents, events and contracts |
| createDate | timestamp | Date on which the project document was created |
| description | text | Description of the project event |
| docType | text | General type name for the project documents (e.g. Event) |
| iconType | text | Actual type of project document (e.g. RFP) |
| owner | text | User who created the project document |
| projectId | text | Unique identifier of the sourcing project associated to the event |
| status | text | State of the project document in the process |
| title | text | User-friendly name of the project document |
| type | text | General categorization code of the project documents (e.g. RFx) |
Stores historical information of the sourcing projects.
| Field | Type | Description |
|---|---|---|
| id | text | Unique identifier of the activity |
| description | text | System description of the activity executed |
| details | text | Indicates the status of the activity (e.g. Completed, Canceled) |
| ProjectId | text | Sourcing project unique identifier related to the historical record |
| realUserName | text | Name of the user who performed the activity |
| timestamp | timestamp | Date on which the activity was executed |
| title | text | User-friendly name of the activity |
| type | text | System categorization of the activity (e.g. Task, Team, etc.) |
Stores all currency conversion rates available in the system.
| Field | Type | Description |
|---|---|---|
| FromCurrency | text | Currency code from which the conversion is done |
| TimeCreated | timestamp | Timestamp on which the record was created |
| ToCurrency | text | Currency code to which the conversion needs to be done |
| Rate | double | Exchange rate of the currency conversion |
This seed file is used to define properties for the due dates. For more information, see Due Dates.
| Field | Type | Description |
|---|---|---|
| Due_date | Text | The name of the due date |
| Due_date_type | Text | The Due date type |
| Fixed_costs | Boolean | An indication whether costs are fixed or time based |
| Cost | Double | Fixed costs: The amount of costs. Variable costs: The amount of costs per Time and Time_type |
| Time | Integer | A number indicating the amount of time in case of time-based costs |
| Time_type | Text | Type of time period for cost calculations. This can be any of the following values: day, hour, minute, second or millisecond |
This seed file has two purposes. The first one is to populate the activity attributes that cannot be obtained from any Ariba tables. The second purpose is to set a preferred activity name when the native name is not wanted.
| Field | Type | Description |
|---|---|---|
| Native_activity_name | text | Primary key of the table. Name automatically given to the activity by the model. This field is the concatenation of the activity title, plus its status. |
| Activity_name | text | Name manually given by the analyst to the activity. |
| Activity_order | integer | Order on which the activity should happen in the process. |
| Activity_type | text | Categorization of the activity (e.g. Classification by Phase) |
| Automated_activity | boolean | Flag which indicates if the activity gets executed automatically or not. Valid values are 1, 0 or blank; the last 2 values mean FALSE. |
Note on Activities variability: The app template comes with the Activity_configuration_raw seed file pre-populated for a standard project template. In SAP Ariba, activities change depending on the template used for the sourcing projects creation. These templates can be customized as much as the business wants; therefore, it will always require adjustments.
| Field | Type | Description |
|---|---|---|
| Activity_status | text | Status for which an activity goes through in the process. |
After an updated csv file is loaded into the Seeds folder, the analyst needs to run the following dbt codes to process the latest changes: dbt seed first and then dbt run. This should be done whenever a change is done to any of the seed files.
| Variable | Type | Description |
|---|---|---|
| display_currency | text | All monetary values will be converted to the selected display_currency. |
| use_document | boolean | When TRUE, all document-related activities will be generated in the app template. By default it is set to FALSE to reduce the amount of activities that are being generated. Too many activities could cloud the view of the Process mining analyst. However, it may be useful for particular clients. |
| use_phase | boolean | This variable is similar to the previous one. It gives the possibility to bring activities related to Phases. This variable may help deepening the analysis, and also could help giving certain sense of order to the process. It is set as FALSE by default to avoid the creation of too many activities. |
| Object | Input Data |
|---|---|
| Sourcing_projects | Currency_conversion_rates, Sourcing_project_events, Sourcing_projects, Sourcing_project_details. |
The app template follows 2 approaches for creating activities:
Each approach follows a different logic in the app template.
Approach 1: activities that can be created from transactional tables.
This activity has a specific model where it was created and the name of the model derived from the activity name.
Sourcing_project_creation_events
| Object | Native_activity_name | Description |
|---|---|---|
| Sourcing Projects | Create sourcing project | Event of creation of the sourcing project. The date comes from the Sourcing_projects transactional table. |
Approach 2: activities that can be created from historical table.
These activities have a specific model where they all were created. By default all of them are based on Ariba Tasks. And it can also add activities based in Phases and Documents.
Relevant considerations:
The activities present in the app template are based on the standard predefined template in SAP Ariba for the sourcing process. However, it is not possible to known in advance which activities will be used across implementations.
The most standard activities were set up in advance in the Activity_configuration_raw seed file mentioned in Seed files. For new activities, the analyst should add them following the steps described in that section.
The Native_activity_name is automatically generated by the model concatenating Title (Task name) with Details (status: created, completed, approved, etc.). If this Native_activity_name does have an Activity_name set in the Seeds file, it will use the latter instead.
As a guideline for naming Native_activity_names that have a status 'Completed' we suggest to name them avoiding their status. Therefore, whenever an activity is actually completed, its name refers to the Title only. This is done to increase clarity in the displaying name of the activities.
Example 1:
Native_activity_name: 'Approval for Final Sourcing Strategy Completed'
Activity_name: 'Approve final sourcing strategy'
On the other hand, all other statuses remain in the activity name.
Example 2:
Native_activity_name: 'Approval for Final Sourcing Strategy Denied'
Activity_name: 'Deny final sourcing strategy approval'
The lack of setups for a particular activity will not break the model.
Sourcing_project_history_events
Below, there are examples of activities derived from the standard template, the object, the activity name assigned to them and their descriptions.
| Object | Native_activity_name | Activity_name | Description |
|---|---|---|---|
| Sourcing Projects | Approval for Final Sourcing Strategy Approved | Approve final sourcing strategy | Final approval done to the sourcing project strategy |
| Sourcing Projects | Evaluate RFI Responses Reviewed | Review evaluation of RFI responses | Review done to the evaluation of the RFI responses |
Sourcing project versions:
In SAP Ariba, whenever some header attributes are changed to a Sourcing Project, the system automatically generates a new version of it, with the same Sourcing_project_ID. The system also keeps a copy of the older version by creating a new Sourcing_project_ID, which is not available in the front end of Ariba (it is only stored in the back end). That new Sourcing_project_ID will not have any historical information; it will only keep the original attributes of the project. However, SAP Ariba APIs can still pull these projects. Therefore, the APIs continue extracting the transactional record for the older versions of the same Sourcing project (this is unwanted). To avoid this issue of duplicating Sourcing projects due to versioning, an inner join was done in Sourcing_projects model. This inner join will bring only Sourcing projects with historical information associated.
Sources for activities: There are a couple of tables that could be used for creating activities in Ariba Sourcing; These tables come from two different APIs,Event_management_API and Sourcing_project_management_API. Choosing both sources would generate too many activities and also some of them would be duplicated. It was decided to use the Sourcing_project_management_API to create the table Sourcing_projects_history table as this was more flexible and also contained all required activities to understand the Sourcing process.
Incremental extraction: If you are using incremental extraction, note that deleted records are not supported. Although in general SAP Ariba does not delete records very often, it means that if a record is deleted in the source system, it will not be deleted in the outputted data set.
Therefor you are advised to perform a full extraction from time to time to make sure that the data is up to date.
Repeated timestamps: In SAP Ariba many activities could happen at the same time, in many stages of the process (e.g. the creation of the Tasks such as 'Assign project team' are automatically done when the Sourcing Project is created). The activity orders for all standard template activities are already populated. It is important that the Analyst populates the Activity_order field for new ones in the Activity_configuration_raw seed file.
Same activities with different name: In SAP Ariba, the same activity can have many different Native activity names. This happens because the field Title, which is the first part of the Native_activity_name field (Native_activity_name = Title + Details), could vary across sourcing projects, depending on the name assigned to the task by the system.
Example:
The activity 'Review RFP Approved'
could have a native name as:
'Review RFP 001 Approved',
'Review Request for Proposal 02 Approved', etc.
To avoid this problem, the Analyst should populate the Activity_name field in the Activity_configuration_raw seed file.
Example:
The previous Native activity names can be renamed as: 'Approve RFP review'.
New Event/document added to the project after the fact: If, for any reason, a new document is added to the project, it means that the Template did not create any Task associated to it, therefore, the user must create them manually (Create document, Approve document, etc). If this is not done, it could happen that all the activities related to that document are going to be missing in the app template. Enabling the variable 'use_document' for displaying document-type activities could potentially solve this problem. Please refer to Dbt variables.